LightGBMのProbabiliy(~~率)を検証・考察してみる

予測モデル精度競争チャンピオン

AIは平均値をちょっと良くした物という定義がありますが、その中でもAI競技の世界では、結局勝ち残るのはLightGBMになるという経験則があります。
DataRobot や様々なクラウドで提供されているAutoMLを利用しても、結局勝ち残るのはLightGBMばかりなので、突き詰めて考えてしまうと、LightGBMを試せば最良の予測モデルが作成できてしまうという印象すらあります。
これはKaggleで上位ランキングを取った半数以上もの勝者が「勾配ブースティング」を使っている(参照:kdnuggets)という記事からもお分かりいただけると思います。一昔前は『決定木バカ』と揶揄される程、全ての課題に対して決定木を当てはめようとする方がいたのですが、最近は…『LightGBMバカ』が一世を風靡してしまっている印象もあります。
複数の予測モデルを比較すると、常にLightGBMのスコアが頭一つ抜きんでてしまうため、仕方ないと言えば仕方ない要素もあるのかもしれません。
第3世代AIの課題
勾配ブースティング法を代表とする第3世代AIですが、予測精度自身は高いのですが、ロジスティック回帰、決定木と比較すると解釈性に欠点があり、評価で利用されるAUCも元々がConfusion Matrixをベースとしていることもあり、ビジネスユーザーに説明すればするほど、話がこんがらがる(Confuseする)という特徴があります。
評価指標に関しては愚直に、『二値分類の評価指標ではAUCを利用する』・『細かい事は考えないで信じてください!』で良い気もしますが、ビジネスサイドに分かりやすくしようという努力もあり、説明時にビジネス用語っぽい物を利用する癖があるため、(これはConfusion Matrix問題でも同じなのですが、一般的に利用されている用語を、むやみに統計・分析の用語として無理やりな適応をしている事もあって、ビジネスサイドとの感覚値が異なってしまい、かえって混乱する事になっている印象がありあます。
予測確率が確率じゃない問題
ロジスティック回帰をはじめとする機械学習での二値分類ではしばしば、モデルから出力されるPropensityScoreやProbabilityを『解約率』や『予測契約率』と翻訳して表記されている事が多いです。
ロジスティック回帰で出力されるPropensityScoreはビジネスサイドでも理解しやすく、予測側でPropensityScoreが0.3の人が100人いると、実際に契約する・解約する割合は30人になるため、しっくり来やすいようです。
予測確率と実際の確率がどれだけ一致しているかを確認するためにはProbability Calibration curvesを使います。
ロジスティック回帰で出力されるのはPropensityScoreなのですが、実際に Probability Calibration curvesに当てはめると、予測確率とほぼ等価になっている事が分かると思います。
Probability Calibration curves — scikit-learn 1.6.1 documentation
When performing classification one often wants to predict not only the class label, but also the associated probability. This probability gives some kind of co…
PropensityScore って一体何?という方は以下のリンクを参照ください
【統計コンセプト】傾向スコアを数式なしで理解する【図解】 » 頑健な妻 (robustwife.com)
傾向スコアと機械学習とprobability calibrationの話 - rmizutaの日記
はじめに RCTが使えない場合の因果推論の手法として傾向スコアを使う方法があります。 傾向スコアの算出はロジスティック回帰を用いるのが一般的ですが、この部分は別にli…

それでは、予測精度が高い(AUCが高い)Random forestのProbability Calibration curvesを見てみましょう
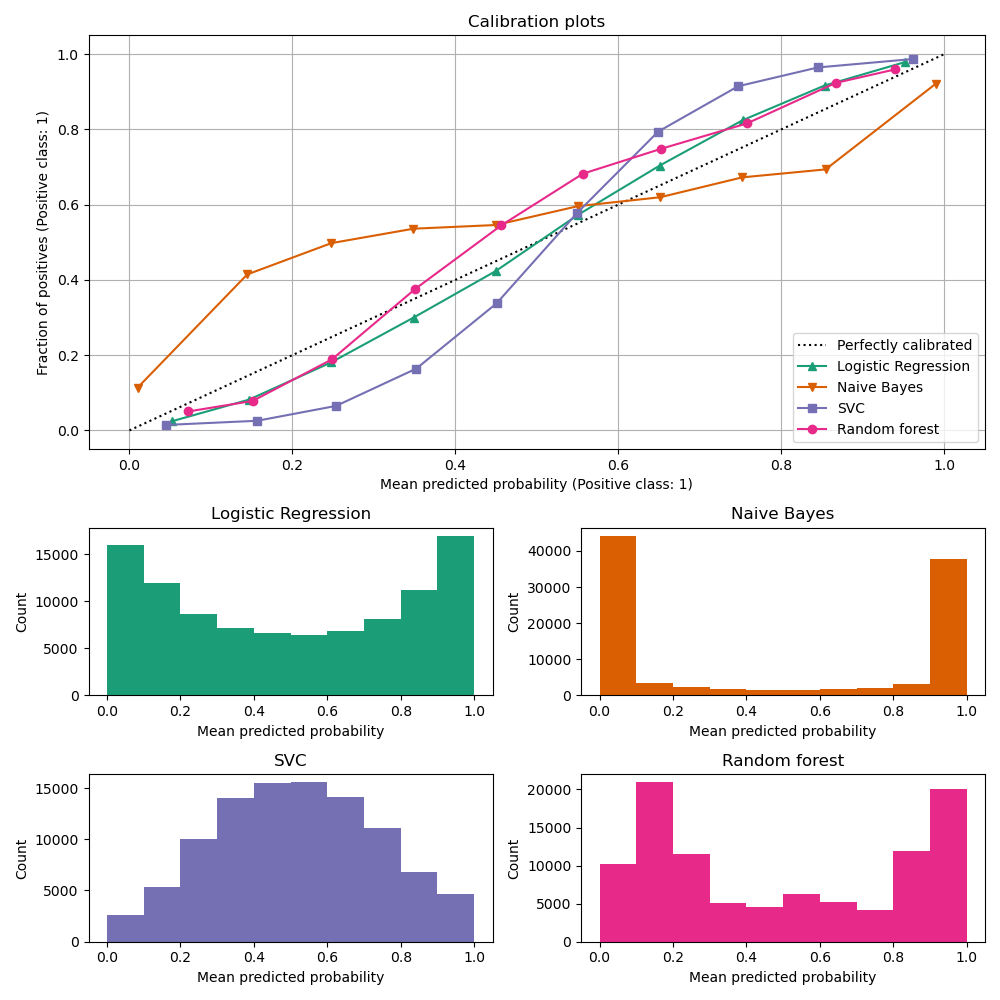
予測確率と実際の確率がどれだけ一致してくれていない事が分かるかと思います。
引用 https://scikit-learn.org/stable/modules/calibration.html
LightGBMのProbabilityとロジスティック回帰の傾向スコアとの違い
LightGBMの仕組みとしては、説明変数にもとづいて、決定木アルゴリズムを実行していきます。
この時、決定木の出力は目的変数(例えば解約とか、制約とか)に対するポイントが出力されます。(プラスもマイナスも発生)LightGBMではこのポイントが蓄積されていくのですが、たまったポイントに対してロジスティック変換を行い、0~1の範囲にした値を振り分けます。この値がProbabilityとなります。
Probability=Shapの積み上げとして理解すれば、この値が傾向スコアと異なる事が理解できるかもしれません(説明の正確性はいったん省略します)
機械学習のモデル評価と説明可能性のための指標 その2。SHAP #機械学習 - Qiita
基本的には決定木を複数回繰り返しているため、その出力の積み上げであると考えればイメージが間違わないかと思います
LightGBMによる物性予測モデルの計算過程を視覚化する #Python - Qiita
#はじめにLightGBM の中身について理解するためにやってみたメモ環境本記事では以下を事前にインストールしておく必要がある。GraphvizPythonnumpypandasma…

結論
- LightGBMから出力されるProbabilityは、ロジスティック回帰で出力されるPropensityScoreとは異なる数値であり、計算の特性上予測確率と実際の確率の一致は考慮しない
- 補足:偏りが大きいデータ(不均衡データ)ではさらにこの差分が顕著に発生する
- LightGBMを利用する際に出力されるProbabilityは~~~率として翻訳せず、〇〇〇スコアと表記する
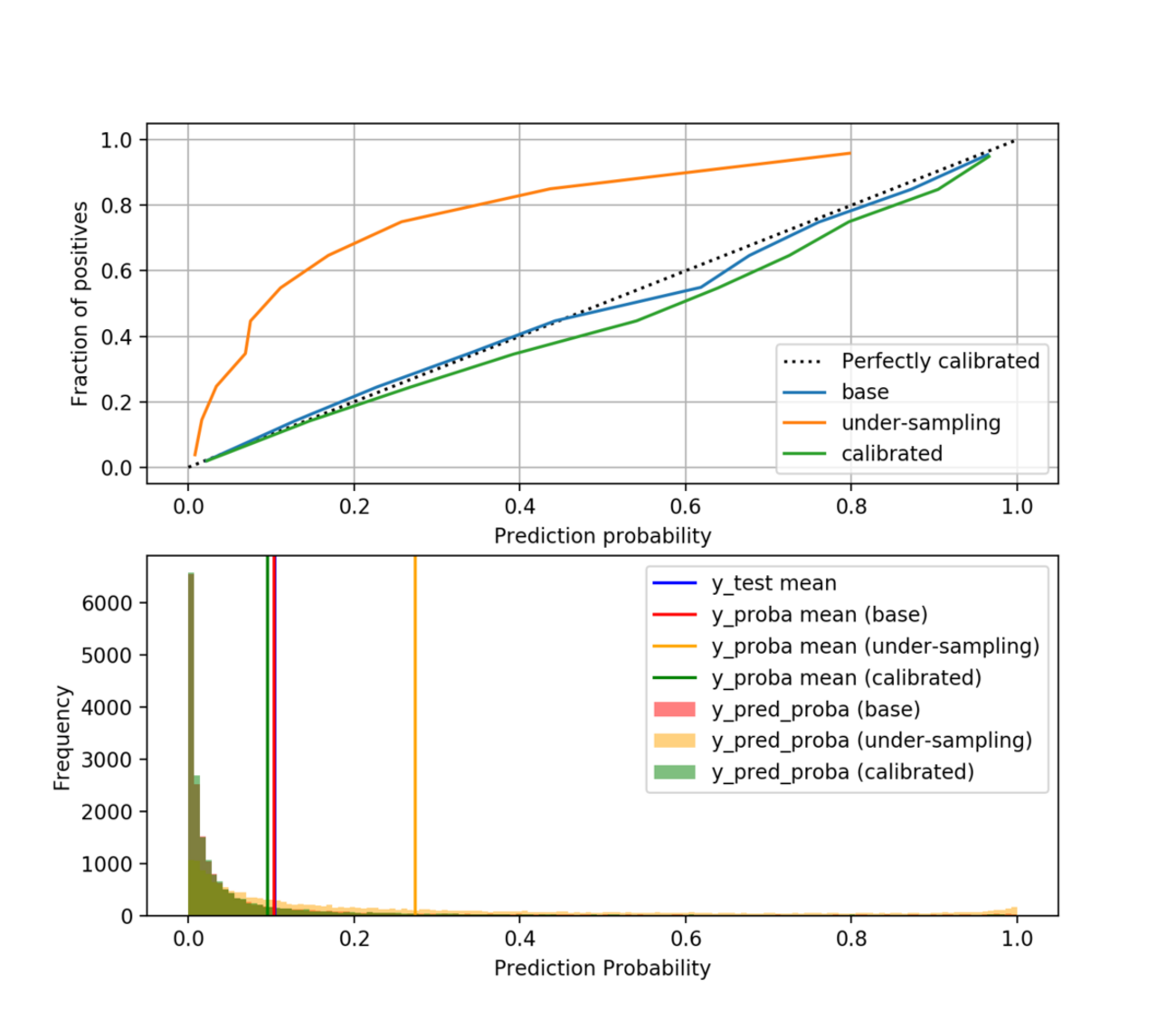
Python: LightGBM で Under-sampling + Bagging したモデルを Probability Calibration してみる - CUBE SUGAR CONTAINER
クラス間の要素数に偏りのある不均衡なデータに対する分類問題のアプローチとして、多いクラスのデータを減らすアンダーサンプリングという手法がある。 データをアンダー…
LightGBMを打ち負かしたモデルとは
小売り流通向けの需要予測システムの予測精度に問題があり、既存のモデルを確認したところ、こちらもLightGBMで作成されていました。実際に移動平均を算出して、比較した所、移動平均よりも予測値が低かったという笑い話がありました。(実話)
当たらない需要予測に関しては過去ポストもご参照ください
どんなに素晴らしいツールも使い方、使いどころ次第ですね。3か月で上記の酷いモデルは修正を行い、現在も商用ベースで利用いただいております。
AutoML業界七不思議
DataRobotにしても、MicrosoftさんのAzureのAutoMLにしても、決定木の出力が出せないのは何故なんでしょうか。結局使い勝手の良さから、SPSS Modelerを別途契約する事になるので、できれば各社様にはご検討いただきたいですよね。(分析結果を解釈する上では一番スムーズな気がしています)
宣伝:SPSSをよろしくお願いいたします。Desktop版をご契約いただいて、ワークステーションにインストールするだけでかなりパワフルに計算実行が可能です(内緒にしろと怒られそう)

